IA & Marketing : la promesse de la data intelligence ! (Part 2)
L’Intelligence Artificielle fait partie comme le Big Data ou la Blockchain de ces concepts technologiques que l’on évoque bien plus qu’on ne comprend vraiment. Les notions à la base de l’IA restent très floues, et on a encore du mal à comprendre comment cela fonctionne concrètement. 
Comprendre l’IA, oui mais…
L’intelligence artificielle est, en tout cas un concept chargé d’affect qui touche à l’essence de l’humain et soulève logiquement autant d’espoirs que de craintes. En imitant l’homme dans l’imaginaire collectif, la technologie peut pour certains, assister l’humain et le soulager, et, pour d’autres, le remplacer et l’aliéner. C’est un peu comme le problème du verre à moitié plein ou à moitié vide. Il faut tout d’abord comprendre que la notion d’intelligence dont on parle dans l’IA est, pour l’instant du moins, focalisée sur un processus unique, qui cherche à reproduire les mécanismes du raisonnement humain sur une problématique bien précise. On parle d’IA faible par opposition à l’IA forte, consciente d’elle-même et capable de simuler les actions et raisonnements humains dans toutes leurs dimensions. Ce qui caractérise l’IA se résume en deux mots : Machine Learning. En effet, alors qu’un programme informatique classique doit prévoir à l’avance tous les cas de figures et les combinaisons d’événements, un programme d’IA basé sur du Machine Learning est conçu pour apprendre tout seul, s’adapter aux situations nouvelles dans le contexte défini et évoluer pour mieux prendre en compte l’avenir. 
Comment la machine apprend ?
Pour apprendre, un système a besoin de données en entrée qui vont lui permettre de s’entrainer pour être en mesure d’effectuer des prédictions sur des nouvelles données qui lui seraient présentées. Cet apprentissage peut être supervisé ou non supervisé. En mode supervisé, le jeu de données fourni pour entrainer le système doit comporter la réponse pour chaque enregistrement, sur la variable à prédire. Ainsi, si vous souhaitez mettre en place un algorithme de scoring de nouveaux clients, vous devez fournir au système un jeu d’entrainement comportant des clients existants avec leurs caractéristiques (prédicteurs) et le score qui est associé à chacun d’entre eux (valeur à prédire). L’apprentissage non supervisé fonctionne sans valeur de référence. Le jeu d’entrainement ne comporte que des caractéristiques à partir desquelles le système est chargé de constituer des groupes. Cette approche correspond aux processus de clustering connus des professionnels des études marketing. Les groupes ainsi définis en détectant des similarités entre les contenus et les individus du fichier, peuvent être étiquetés a posteriori par l’expert « humain » Data Analyst après analyse de leurs caractéristiques. Après cette phase d’apprentissage, il est possible d’interroger le système sur des nouvelles données pour avoir un pronostic en fonction de ce qu’il a appris. Cette interrogation peut être ponctuelle ou en direct. Le premier cas correspond à un usage analytique, où l’expert Data Analyst utilise le programme d’IA pour qualifier un fichier de données, en d’autres termes pour identifier les données pertinentes et exclure les données aberrantes qui pourraient fausser/biaiser l’analyse ou le modèle généré. Quant au deuxième cas, il correspond à une interaction en temps réel avec l’algorithme d’IA au travers d’une interface dynamique qui permet de communiquer avec la machine. Ainsi, l’expert humain agit sur la machine par exemple pour : identifier des profils bien précis, isoler des comportements émergeants, identifier des signaux faibles, évaluer les caractéristiques de certains segments pour déterminer les actions à mener, etc. C’est le cas de l’algorithme d’IA développé par la startup française FANVOICE, qu’elle utilise pour analyser les contenus des campagnes de co-création et d’innovation menées sur sa plateforme, pour de nombreuses grandes marques dans l’énergie, Internet de l’objet, alimentaire, banque, assurance, etc. 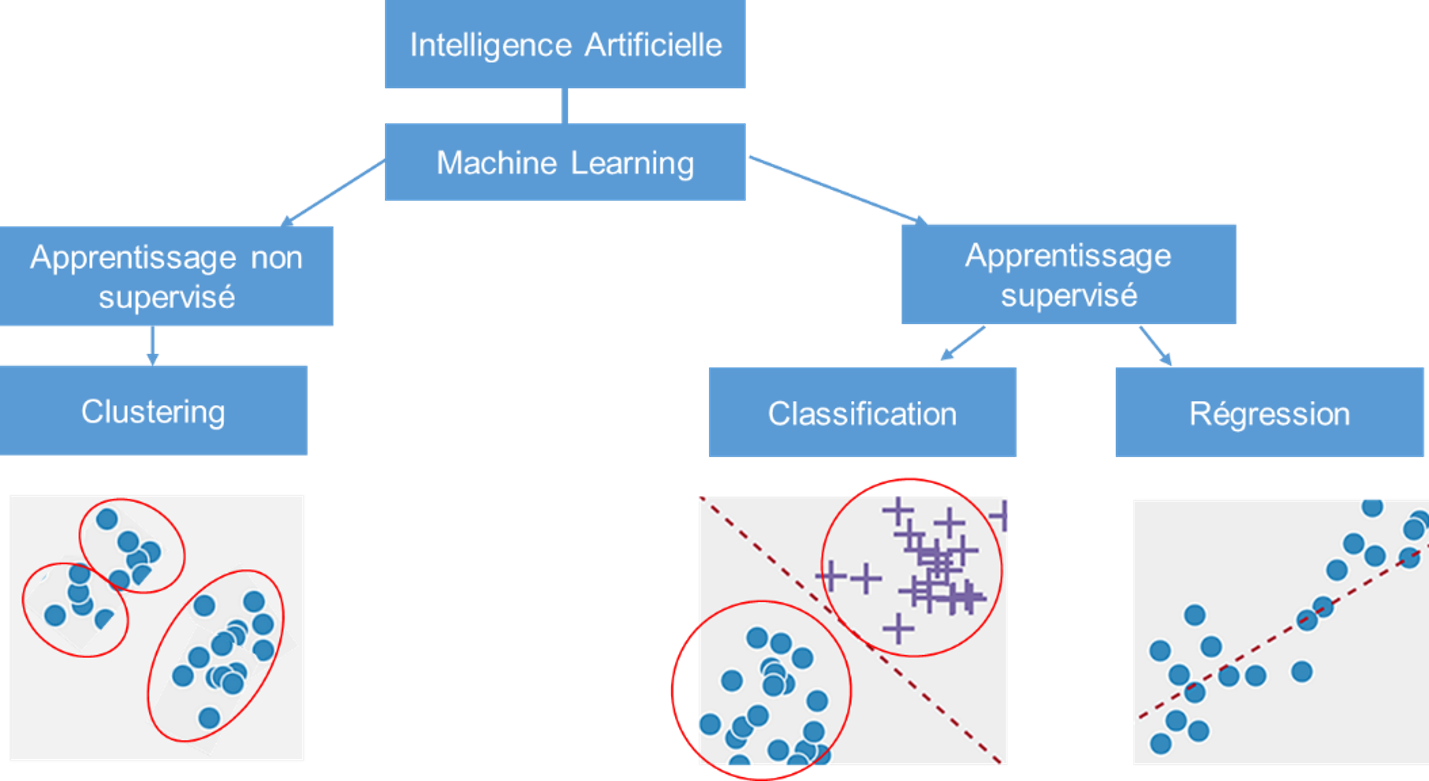
Quelles sont les clés de réussite d’un apprentissage pertinent de la machine chez FANVOICE ?
La qualité des données est bien sûr essentielle pour un apprentissage pertinent de la machine. Il est donc important de veiller à plusieurs paramètres pour concevoir un corpus de données de qualité :
- Taille du fichier : un corpus trop petit ne permettra pas d’obtenir un modèle de qualité. Les règles classiques d’échantillonnage et de nombres utilisées en Market Research s’appliquent aussi dans ce cas.
- Structure des campagnes : les campagnes powered by FANVOICE intègrent une cartographie d’inspiration créée à partir d’un design et d’une méthodologie marketing qui favorisent un recueil de données ciblées, en répondant à une problématique précise déclinée en thématiques. Ainsi, cette cartographie d’inspiration, bien conçue pour traduire la problématique de la marque, permet de guider les participants en les invitant à s’exprimer sur des sujet utiles qui répondent aux objectifs assignés à la campagne.
- Animation et modération : l’animation des fils de discussion de la plateforme par un Community Manager et par un Expert projet contribue à générer des contenus riches et pertinents au regard de la problématique adressée, et donc de contribuer de prime abord à un modèle d’analyse pertinent et porteur d’insights.
- Représentativité des données : les données en entrée doivent intégrer toutes les nuances que vous souhaitez dégager et exclure les données aberrantes qui pourraient fausser l’analyse (par exemple via une liste de stop words adaptée à la campagne).
- Qualité des prédicteurs : les prédicteurs doivent permettre à l’algorithme de dégager un modèle d’analyse pertinent. La présence d’éléments inutiles (bruits) peut fausser le système et aboutir à une modélisation inefficace.

L’humain agit sur la machine et reste au cœur du processus décisionnel !
L’IA ne fait pas disparaître l’expertise humaine, bien au contraire. Les algorithmes d’intelligence artificielle basent leur fonctionnement sur ce qui leur est fourni au départ. Leur capacité de calcul rapide et de combinaisons complexes dépasse les nôtres pour gagner toujours en précision et en efficacité. Enfin, les machines seules, aussi efficaces soient-elles, ne peuvent acquérir ni sagesse ni bon sens, propriétés – non mathématiques donc non transformables en algorithmes – propres à l’être humain. Kasparov, le précise dans sa parole : « Les machines font des calculs. Nous comprenons les choses. Les machines reçoivent des instructions. Nous avons des buts. Les machines ont pour elles l’objectivité. Nous avons la passion. Nous ne devrions pas avoir peur de ce que nos machines peuvent faire aujourd’hui. Nous devrions plutôt nous inquiéter de ce qu’elles ne peuvent toujours pas faire car nous aurons besoin de l’aide de ces nouvelles machines intelligentes pour faire de nos rêves les plus fous une réalité »  La raison d’être de l’IA n’est donc pas de remplacer l’humain mais au contraire de lui simplifier la tâche, tout en le replaçant au centre de son activité. La course à la pertinence et à la performance des données pour en extraire de la data intelligence est en marche !
La raison d’être de l’IA n’est donc pas de remplacer l’humain mais au contraire de lui simplifier la tâche, tout en le replaçant au centre de son activité. La course à la pertinence et à la performance des données pour en extraire de la data intelligence est en marche ! 
Rejoignez les marques connectées à leurs clients et collaborateurs
Nous sommes à votre disposition pour échanger sur notre univers des communautés
LES ACTUALITÉS SIMILAIRES
VOIR TOUT LES ACTUALITÉS
Déc 2024
Etudes
Études de marché : Optimisation avec l’intelligence artificielle
Révolutionner les études de marché grâce à l’intelligence artificielleLes études de marché traditionnelles sont confrontées à de nombreux défis. Les volumes de données explosent, les processus sont lents et les erreurs fréquentes. Les comportements des consommateurs sont plus variés. Ces changements rendent les approches classiques obsolètes. L’intelligence artificielle (IA) offre une solution. Elle réduit les coûts, accélère l’analyse et améliore la précision. L’IA permet de traiter des données variées et de mieux comprendre les comportements des consommateurs.Découvrez comment l’IA révolutionne les études de marché et les transforme en moteurs d’innovation.Obtenez des résultats optimaux grâce à l’IAÀ l’ère de l’hyperconnectivité, le volume de données généré quotidiennement dépasse largement les capacités humaines. Fanvoice se distingue comme une solution puissante et innovante dans les études de marché. Dotée d’outils ...

Mai 2025
Actualités
Solution d’écoute participative : engagez vos communautés
Et si écouter vos communautés (clients, collaborateurs, partenaires) devenait un vrai levier de performance ? Fanvoice est une solution d'écoute participative qui vous aide à mieux comprendre les attentes de vos clients, collaborateurs ou partenaires. Et à transformer leurs idées, retours et ressentis en actions concrètes. Simple à prendre en main, cette plateforme vous permet de créer un lien durable avec vos parties prenantes. Elle s'adapte à vos enjeux, qu'ils soient liés à l'innovation, à l'expérience client, au marketing ou à la RSE Pourquoi choisir une solution d'écoute participative ?Avec Fanvoice, vous pouvez :Explorer les attentes réelles de vos ciblesAméliorer la satisfaction et l'expérience clientCo-créer et co-construire vos produits et servicesLancer vos innovations avec plus de certitudesRéduire le coût de vos études tout en gagnant en qualitéGrâce à cette solution d'écoute participative, vos communautés deviennent une ressource ...

Juil 2025
Actualités
Qu'est-ce que le bêta-test ?
Avant de lancer un nouveau produit ou service, une question revient toujours : est ce qu'il répond vraiment aux attentes du marché ? C'est là qu'intervient le bêta-test, une étape stratégique trop souvent négligée. Concrètement, le bêta-test consiste à faire tester votre produit par un panel de vrais utilisateurs ciblés, avant sa sortie officielle. Cette étape vous permet de récolter des retours concrets, d'identifier d'éventuels points de friction, et d'ajuster ce qui doit l'être pour garantir une expérience fluide et convaincante dès le lancement. Pourquoi intégrer le bêta-test dans votre stratégie produit ?Dans un marché saturé, une simple bonne idée ne suffit plus. Il faut qu'elle fonctionne parfaitement pour ceux à qui elle s'adresse. Le bêta-testing vous aide à : Identifier les améliorations nécessaires à apporter en amontComprendre les usages réels et les attentes des utilisateurs Réduire les risques d'échec au lancementEngager vos ...

Oct 2024
Actualités
La co-création : levier d’innovation et de croissance
Aujourd’hui, les entreprises ne peuvent plus innover seules. Pour créer des produits, services ou expériences vraiment utiles et efficaces, il est essentiel d’impliquer les personnes concernées : clients, salariés, partenaires… C’est ce que permet la co-création. En misant sur l’écoute et la participation, cette méthode aide les entreprises à mieux comprendre les attentes du marché, à gagner en efficacité, et à renforcer la confiance autour de leur marque. Dans cet article, découvrez pourquoi la co-création est devenue un outil indispensable et comment des entreprises comme Bouygues Telecom, SNCF ou Eiffage l’utilisent avec succès grâce à Fanvoice.Qu’est-ce que la co-création ?La co-création ne se limite pas à une simple approche de marketing, mais englobe également une stratégie d'innovation collaborative. Elle va au-delà de la participation des clients, des employés et des partenaires dans le processus de création de valeur. En encourageant la ...

Nov 2024
Actualités
Stratégies d’innovation: l'IA pour mieux satisfaire et vendre plus
Avez-vous déjà conçu un produit qui n’a pas rencontré le succès espéré ? Ou investi des ressources dans des tests interminables, seulement pour constater que les attentes des clients avaient évolué ? Peut-être avez-vous aussi constaté que vos concurrents prennent de l'avance avec des solutions plus efficaces et agiles ? Ces scénarios sont malheureusement courants pour beaucoup d'entreprises qui n’ont pas encore adopté des stratégies d'innovation basées sur l’IA.Et si vous pouviez changer cette réalité ? L’IA ne se contente pas de résoudre ces problèmes : elle vous aide aussi à anticiper les attentes de vos clients, à réduire vos coûts, et à accélérer votre innovation. Découvrez dans cet article comment l’IA peut transformer vos défis en opportunités et booster votre succès.Fanvoice dévoile des stratégies d'innovation en s'appuyant sur plateforme tout-en-un alimentée par l'IA.Comprendre les besoins des clients est un défi constant pour les ...

Nov 2014
Actualités
Lego fait le plein d'idées avec sa plateforme de co-création
Exploration de la Magie de la Co-création chez Lego : Découvrez Lego Ideas et ses Jouets UniquesÇa vous dirait de devenir riche en participant à la création de nouveaux jouets Lego ? Il suffit de participer à la démarche de crowdsourcing lancée par la marque... et de séduire la communauté. Si vous aimez le crowdsourcing, vous connaissez sûrement déjà la version beta de la plateforme de co-création Lego version jouets de Lego, connue sous le nom de “Lego Cuusoo”. Eh bien, depuis le 30 avril, le système a évolué et se présente sous sa version définitive sur le site officiel de l’entreprise : Lego Ideas (notez que le terme “Brand X Ideas” semble devenir un classique du métier).La marque Danoise est réputée pour ses créations originales et amusantes, telles que la reproduction de scènes de livres ou films populaires, monuments historiques ou personnages célèbres. Il faut le reconnaître, Lego ne manque pas d’idées, mais elle ne peut pas penser à ...

Juil 2016
Etudes
L’apport de l’analyse sémantique : le dépassement du clivage qualitatif vs quantitatif
Il existe de grandes oppositions dans l’univers des sciences sociales et des études de marché : entre "observation et explication", entre "mesure et analyse du comportement" et avant tout entre "qualitatif et quantitatif". Aujourd’hui, les principaux instituts d’études sont organisés selon une logique de distinction de ces compétences, ayant en général un pôle “quali” spécialisé et à part, amené parfois à collaborer avec les quantitativistes. Ce modèle évolue aujourd'hui avec l’analyse sémantique. Voyons comment...L'approche quantitative et qualitativeComme nous le savons, l’objectif du quantitatif est celui de la mesure alors que le qualitatif s’intéresserait aux processus. En conséquence, le quantitatif viserait les tests statistiques "confirmatoires" et le qualitatif les procédures "exploratoires". En somme, le but du quantitatif serait de mesurer un phénomène et celui du qualitatif de comprendre son sens. Ces oppositions deviennent stériles ...

Sep 2016
Crowdsourcing & co-création
Banques, assurances & co-création / Episode 3
Voici le 3e volet de notre saga sur "la co-création et les entreprises de la finance".Cet article détaille un peu plus un exemple que nous connaissons très bien et pour cause, il s’agit d’un client de FANVOICE : DIRECT ASSURANCE, qui a impliqué une communauté de clients dans la co-construction de sa nouvelle offre d’assurance auto YOUDRIVE...La Banque et l’Assurance sont décidément des secteurs décidés à innover, vite et bien.Nous avons pu l’observer à travers nos différents articles : plusieurs initiatives participatives ont été lancées par les plus grandes enseignes à travers le monde, en Australie, aux USA, en Europe, pour réinventer la banque, identifier de nouveaux usages et imaginer des produits d’assurance pour y répondre (nous parlons d’ailleurs de ces initiatives dans le livre blanc sur “l’innovation dans la Banque” qui sera publié à la rentrée). Particulièrement intéressés par cette approche, nous avons lancés plusieurs travaux ...
